1. Giới thiệu chung về Phân Cụm (Clustering)
Phân cụm (Clustering) là một kỹ thuật phân tích dữ liệu trong lĩnh vực khai phá dữ liệu (Data Mining), nhằm chia một tập dữ liệu thành các nhóm hoặc cụm dựa trên độ tương đồng giữa các đối tượng. Đây là kiến thức thiết yếu đối với Data Analysts:
Các ứng dụng thực tế của phân cụm bao gồm:
- Phân nhóm khách hàng: Giúp các doanh nghiệp phân loại khách hàng theo hành vi hoặc nhu cầu để tối ưu hóa chiến lược tiếp thị.
- Phân loại văn bản và hình ảnh: Sử dụng trong phân tích ngôn ngữ và xử lý hình ảnh.
- Phân tích sinh học: Nhằm phát hiện các nhóm mẫu gen hoặc phân loại dữ liệu sinh học trong nghiên cứu y tế.
Phân cụm là một kỹ thuật cốt lõi của Data Analysts, giúp trong việc khám phá dữ liệu, tạo dựng nhóm đối tượng, và tối ưu hóa các mô hình học máy.
2. Các loại Phân Cụm Cơ Bản
Có hai phương pháp phân cụm chính trong phân tích dữ liệu, mỗi loại có cách tiếp cận và ứng dụng khác nhau.

Phân cụm phân vùng (Partitional Clustering)
Phân cụm phân vùng, trong đó K-means là ví dụ điển hình, là phương pháp phân chia dữ liệu thành một số cụm nhất định được xác định trước (thường là k cụm). Các điểm dữ liệu sẽ được gom lại vào các cụm sao cho các đối tượng trong cùng một cụm có tính chất tương đồng cao nhất, dựa trên một tiêu chí đo lường như khoảng cách Euclid.
Phương pháp này thích hợp khi có dữ liệu đồng nhất hoặc khi các nhóm không có mối quan hệ phân cấp. Phân cụm phân vùng thường nhanh và hiệu quả trên các tập dữ liệu lớn.
Phân cụm phân cấp (Hierarchical Clustering)
Phân cụm phân cấp xây dựng một hệ thống phân cấp để nhóm các đối tượng. Có hai phương pháp chính:
- Phân cụm phân cấp tổng hợp (Agglomerative Clustering): Bắt đầu với mỗi đối tượng là một cụm riêng lẻ, sau đó ghép các cụm gần nhau nhất cho đến khi tất cả chỉ còn một cụm duy nhất.
- Phân cụm phân cấp phân chia (Divisive Clustering): Bắt đầu với một cụm lớn bao gồm toàn bộ dữ liệu và liên tục chia nhỏ cụm lớn nhất dựa trên sự khác biệt giữa các đối tượng.
Phương pháp này phù hợp khi muốn phân tích sự tương đồng theo cấp bậc giữa các đối tượng, nhưng với dữ liệu lớn, nó đòi hỏi nhiều tài nguyên tính toán.
Để hiểu hơn về cách thức hoạt động của thuật toán phân cụm thì mình sẽ lấy một ví dụ để thực hiện phân tích cho mọi người dễ hình dung hơn. Mô tả về ví dụ có trong hình dưới đây.

3. Thuật Toán K-means: Tổng Quan và Cách Hoạt Động
Thuật toán K-means là một trong những thuật toán phân cụm phổ biến, dễ hiểu nhất. K-means hoạt động bằng cách phân chia dữ liệu thành k cụm riêng biệt, với mỗi cụm có một "tâm cụm" (centroid). Các bước chính của thuật toán K-means như sau:
Bước 1: Khởi tạo ngẫu nhiên k tâm cụm
Có nhiều cách và phương pháp để xác định k tâm cụm. Nhưng Elbow, Silhoutte coef, Gap statistic là các phương pháp phổ biến nhất.
3.1. Elbow: Ý tưởng là tìm kiếm những quan sát có nhiều điểm tương đồng với nhau nhất.

- Bước 1: Xác định A - trung bình cộng bình phương khoảng cách từ điểm đến tâm cụm với k lần lượt bằng 1, 2, 3, v.v (thường k không quá 10)
- Bước 2: Điểm k=n cần tìm sẽ là điểm mà có A thấp hơn điểm liền trước và liền sau. Trong trường hợp có 2 điểm thỏa mãn điều kiện, ưu tiên k nhỏ hơn.

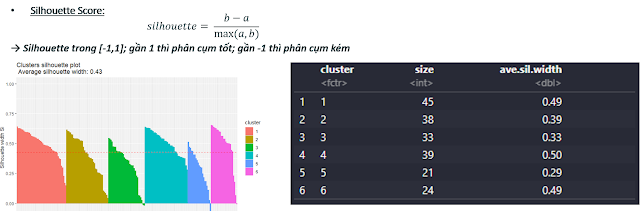
3.2. Silhoutte coef: Ý tưởng là tập trung cả về điểm tương đồng và điểm khác biệt.
Cách Silhoutte coef hoạt động như sau:
- Xác định ngẫu nhiên k cụm
- Tính khoảng cách của các điểm đến các điểm trong cụm (điểm tương đồng với các điểm trong cụm) và khoảng cách từ điểm đến các cụm gần nhất (khoảng cách từ tâm cụm này đến tâm cụm kia gần nhất) (điểm khác biệt so với các cụm khác).
- Nếu khoảng cách từ một điểm đến các điểm trong cụm lại lớn hơn khoảng cách từ điểm đó đến điểm ngoài cụm thì điểm đó đang bị phân vào cụm sai, điều chỉnh bằng cách chuyển điểm đó đến cụm kia.



3.3. Gap statistic: Ý tưởng là tập trung về điểm tương đồng
Cách Gap statistic hoạt động như sau:
Tương tự như cách Elbow hoạt động nhưng. Gap Statis tính khoảng cách giữa các điểm trong cụm.

- Bước 1: Tính giá trị trung bình khoảng cách các điểm trong cụm với k=1, 2, v.v (k thường nhỏ hơn 10).
- Bước 2: Điểm k=n cần tìm sẽ là điểm mà có gap statistic cao hơn k=n-1 và k=n+1

Bước 2: Gán ngẫu nhiên mỗi quan sát vào một cụm ban đầu từ 1 đến k

Bước 3: Thực hiện quy trình cho đến khi việc gán cụm ngừng thay đổi

Bước 4: Đánh giá chất lượng thuật toán với bài toán
4. Một Số Thuật Toán Phân Cụm Khác và So Sánh Ngắn
Ngoài K-means, còn có các thuật toán phân cụm khác như:
- DBSCAN: Phân cụm dựa trên mật độ điểm, phù hợp với dữ liệu có nhiễu hoặc dữ liệu không đồng nhất.
- Hierarchical Clustering: Phân cụm theo cấp bậc, hữu ích khi cần phân tích cấu trúc phân cấp của dữ liệu.
K-means thường được chọn khi dữ liệu đồng nhất và cần phân cụm nhanh chóng, trong khi DBSCAN hiệu quả với các cụm có hình dạng bất thường và Hierarchical Clustering thích hợp cho phân tích đa cấp.
Kết luận
Phân cụm là một công cụ quan trọng trong công việc của một người phân tích dữ liệu, giúp tìm hiểu cấu trúc và bản chất của dữ liệu. Trong đó, thuật toán K-means nổi bật với tính đơn giản và hiệu quả. Tuy còn một số hạn chế như phụ thuộc vào giá trị k và khó xử lý dữ liệu có hình dạng cụm phức tạp, K-means vẫn là lựa chọn phổ biến trong nhiều ứng dụng thực tế. Để đạt được kết quả phân cụm tối ưu, các bạn cần linh hoạt trong việc chọn thuật toán và đánh giá kết quả dựa trên đặc điểm của dữ liệu.
LINK thực hành K-means trên R có tại đây
chào cậu
Trả lờiXóaTrong bài viết tiếp theo, mình sẽ cùng tìm hiểu về các thuật toán phân loại nhé ^^
Trả lờiXóaCảm ơn các bạn! Tips này rất thực tế trong công việc của DA
Trả lờiXóa